Using the CPF code
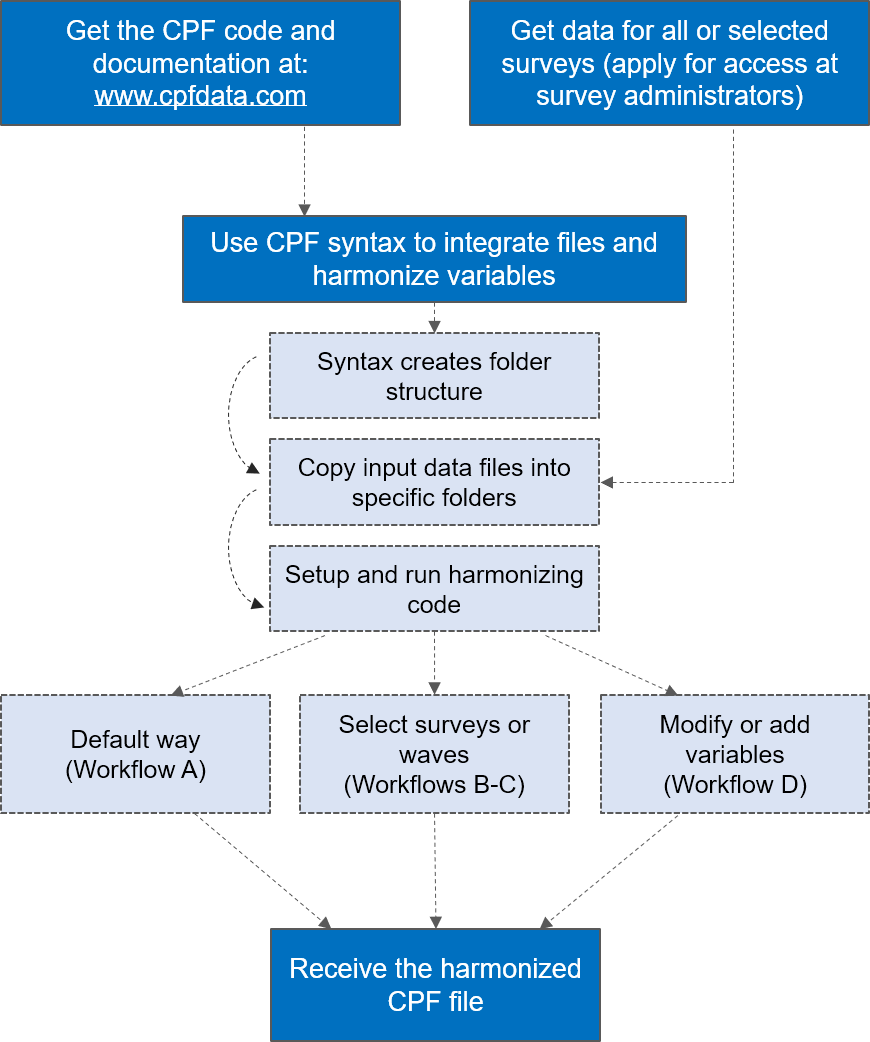
The CPF provides free of charge and full access to the programming code (Stata syntax in do-file format). The code allows combining the separate raw survey data into a single harmonised data file.
The Manual explains how to work with the syntax, and the Codebook describes all variables (both availible here).
Users must first apply for access to each of the origin datasets independently at national administrator institutions. Access is free of charge, but in most cases, users must describe their research goals and sign a contract. When access is granted, the files can be extracted to specific CPF folders.
The open-source character of the code allows for developing and extending areas of application. Users can either follow the default workflow and run the code unchanged, or modify and improve it (e.g. select countries, add new waves, add new or modify existing variables).
CPF version 2.0 was built on data versions released in spring 2025. Backward compatibility with older releases is not available for some variables or surveys due to changes in variables names and file structure (but the syntax can be modified).
Data structure
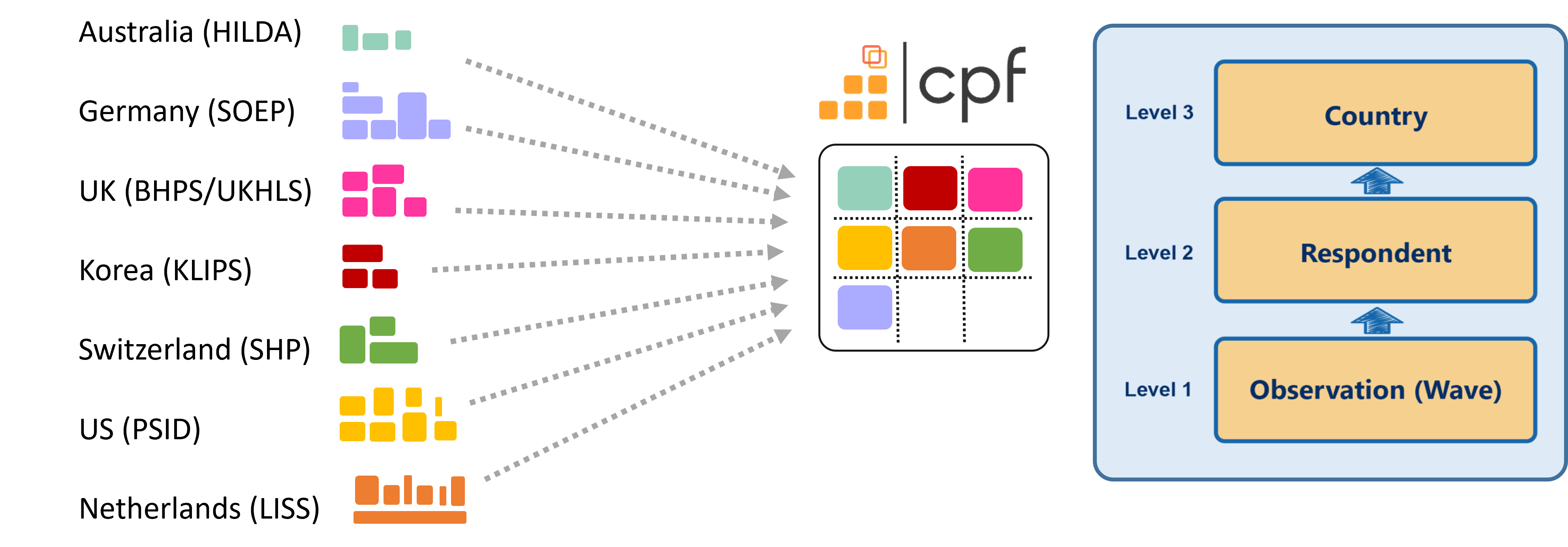
CPF is a comparative panel dataset with a three-level hierarchical structure: repeated observations from multiple waves (level-1) are clustered within individuals (level-2), and individuals are clustered within countries (level-3).
CPF syntax
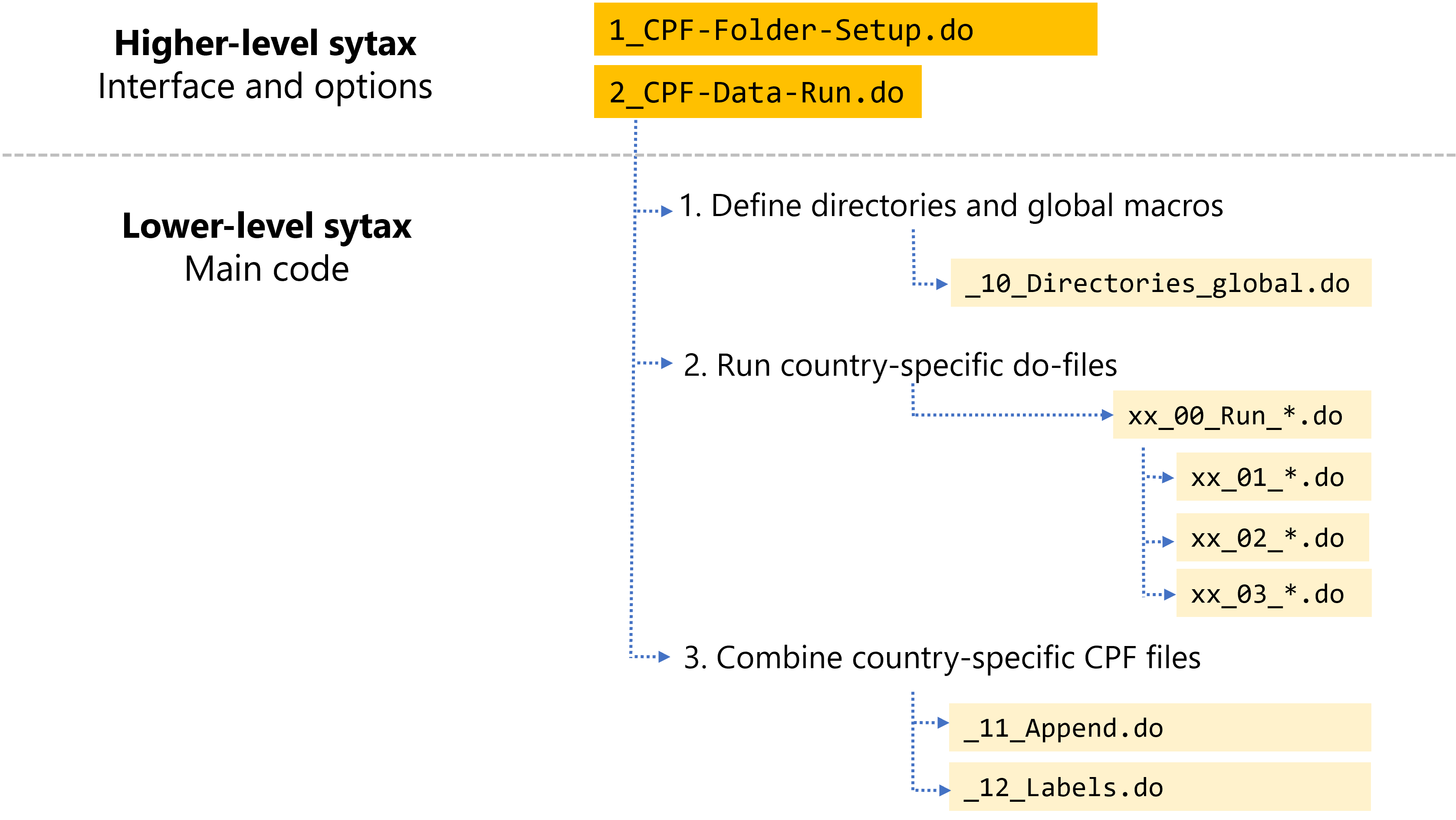
The syntax is designed at two levels: higher and lower. Two higher-level syntaxes work as an interface and allow to fill in the necessary information (e.g. file directory) and setup options for harmonisation (e.g. which surveys to include). As meta-level codes, they scall all the necessary codes from a more complex structure of lower-level syntaxes.
For each survey, there are separate lower-level syntaxes, and the algorithms are designed differently. But they all lead through the same three steps: the first constructs initial separate country data in a long format by merging origin files, the second harmonises variables within countries according to the common template, and the third selects comparative samples. The process results in separate datasets with the same data structure for each country. Then, all country files can be combined into the single CPF harmonised dataset using a higher-level syntax.
How to start using the CPF:
-
Download the latest version of CPF code. Unpack the entire folder structure with CPF-do-files to 11_CPF_in_syntax.
-
Run 1_CPF-Folder-Setup.do according to instruction in the do-file.
-
Copy the original input datafiles (e.g. from SOEP) to specific folders (e.g. C:\CPF\02_Country_Data_Origin\06_SOEP\data).
-
Go to 2_CPF-Data-Run.do and follow instructions regarding the worfklows.
Workflows
There are four general ways of working with the CPF syntax (which we call workflows). Workflow A describes the basic approach, workflows B, C and D refer to modifications of the existing syntaxes.
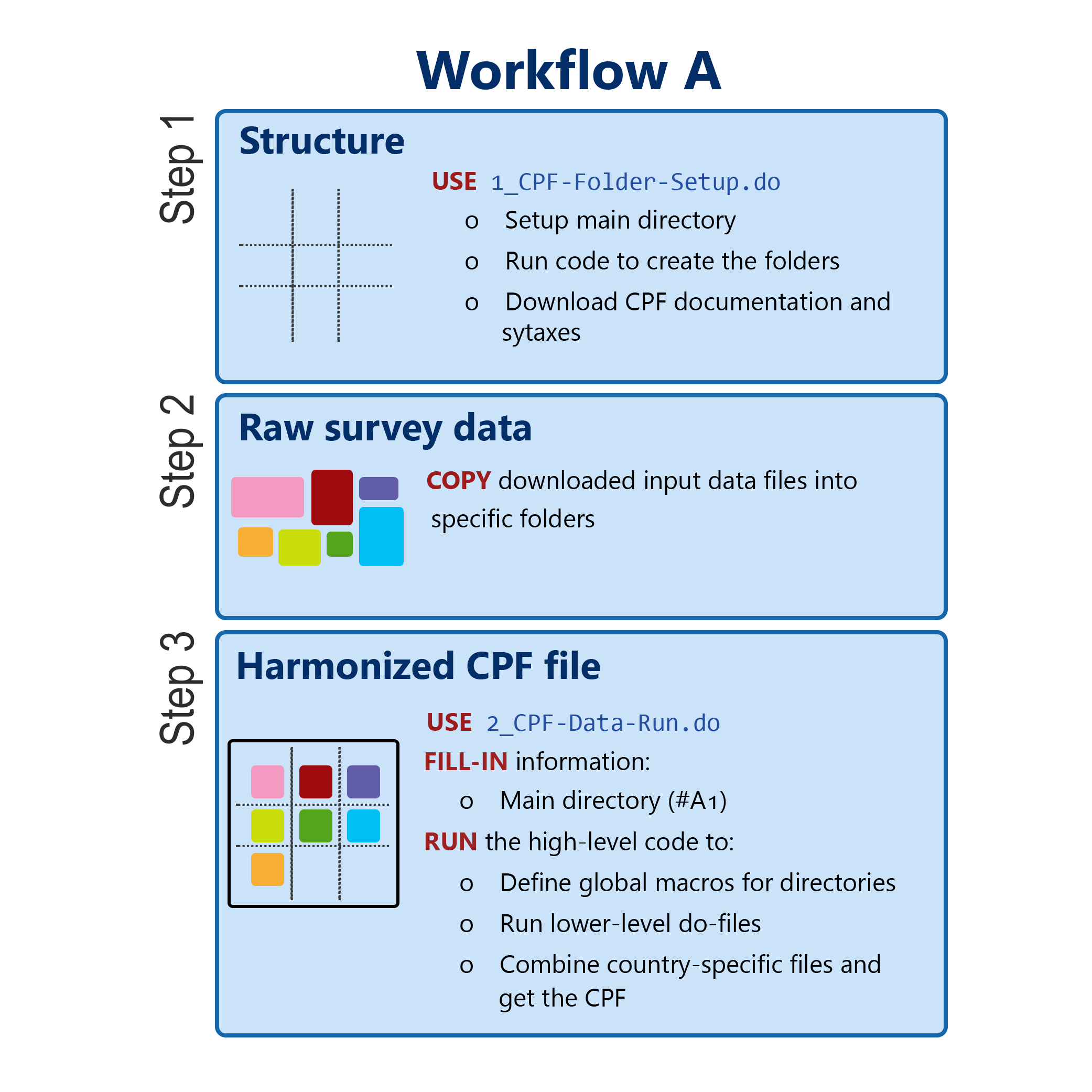
Workflow A is the default and basic way of working with the CPF code. It leads from the raw data to a CPF harmonized dataset without any modifications. Users only have to fill in basic information, such as the directory, and run the code.
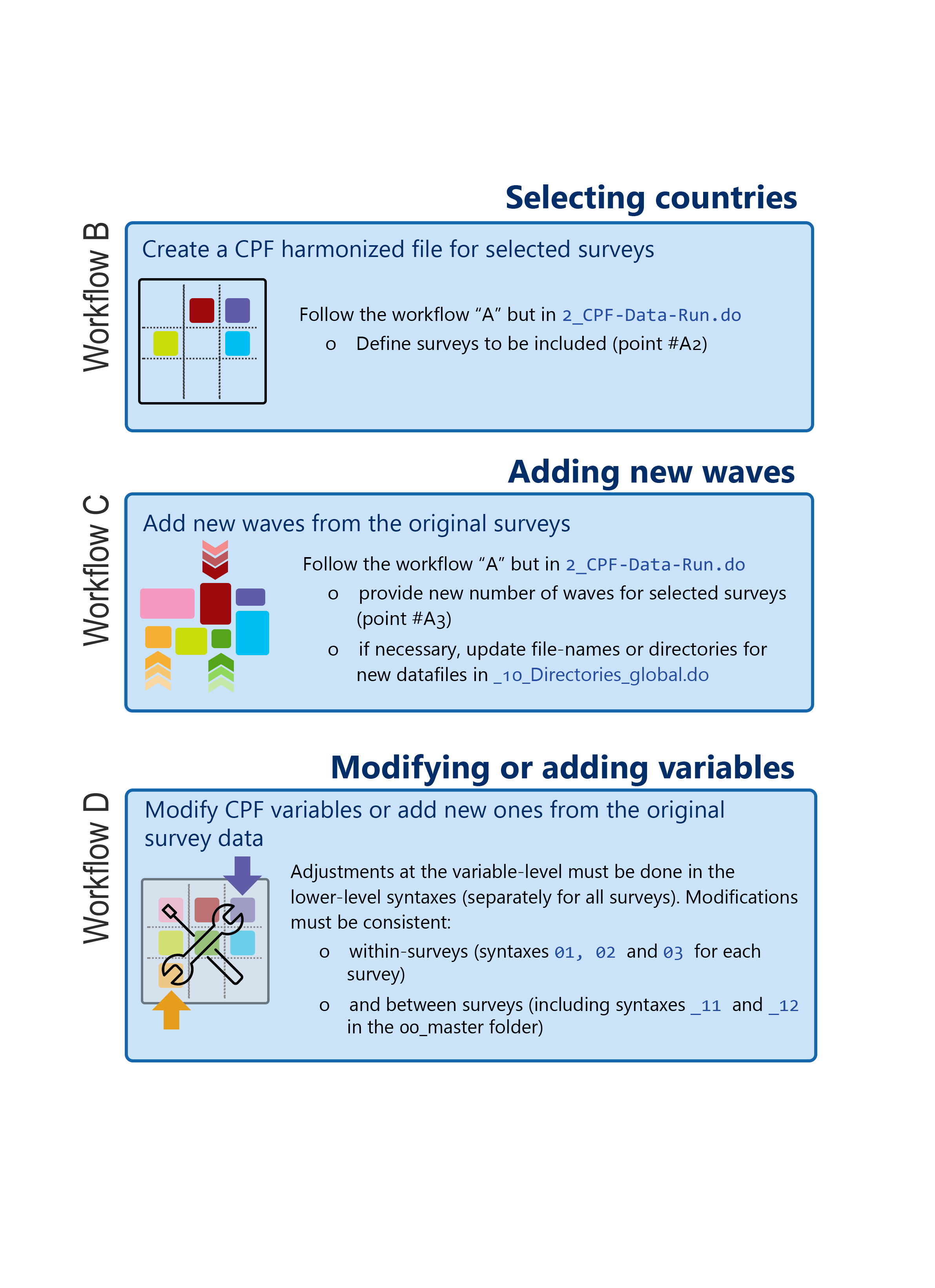
Workflow B allows selecting surveys to be included in the harmonized CPF dataset.
Workflow C serves to add new waves when they become available for the surveys.
Workflow D refers to all other modification of the existing structure of the CPF data. Users can modify existing variables or add new ones, as well as modify the criteria for sample selection. Any adjustments of this type must be done in the lower-level syntaxes, separately and consistently for all surveys and for the master-syntaxes.
</div>
Comments